


1. What is intelligibility?
The state or quality of being understood. It can apply to an idea or a writing, but in our context it relates to the spoken word and, less commonly, to music.While audio professionals are concerned that the intelligibility of the systems they sell or rent isn't not a problem in the applications and locations where they are used, it is a concept that could be applied to an unamplified sound source. For example, on the stairs of a 20-story building it will be difficult for two people to understand each other, even if they are speaking loudly, if they are separated by many floors. Or, if a parish priest decides to give Mass without amplification on a day of poor attendance in a reverberant Catholic cathedral, it will be difficult for people to understand the sermon from the farthest pews even if the priest has a powerful voice. Likewise, it will be difficult to make ourselves understood on the street above the roar of a pneumatic drill or a crowded demonstration (even with the Lombard Effect EL), and we will hardly be able to decipher which piece is being played by a street musician in those same conditions.
Although intelligibility may depend on the quality of a sound system, the level of ambient noise or reverberation, it is also affected by the intelligibility of the speech itself. For example, a speaker with poor diction, a different accent, a muffled voice or speech that is too fast can be difficult to understand in any situation. Also, not all languages are equally intelligible and listeners may not be native speakers with different levels of listening comprehension. Similarly, simple words in a familiar context will be easier to understand. (When there is hunger at home, everyone understands "Lunch's ready!"...)
2. Can everybody undertand me at the back?
Objective and subjective intelligibility measurement
Intelligibility is usually important, particularly for speech; after all, that is the reason why we speak or play a recorded message (although sometimes we would prefer a boring and unnecessarily long speech to be lost in the echo of the room!) In certain applications, that importance can even mean the difference between life and death, as in the case of voice alarm (VA) systems.This is why an attempt is made to quantify the level of intelligibility, which can be done either subjectively or objectively.
2.1 Subjective measurement
In this first case we could ask the audience if everyone understands. In a more scientific way, what is usually done is to use lists of purposely selected phonetically balanced syllables or words. The words can be placed within a sentence that provides a context that facilitates understanding, or they can be pronounced or reproduced one by one. A group of people take a test in which they either select each word from a list of words or have to write it down. For these tests to be statistically valid, the lists must contain enough words (a minimum of 50) and they have to be carried out with a sufficient number of people (with verified hearing), at sufficient sessions and (if applicable) locations.2.2 Objective measurement
We humans are unreliable when it comes to subjective issues, as we depend on many variables such as our mood, so subjective intelligibility tests are expensive and time-consuming if they are to achieve a reliable result.Therefore, there are different objective methods of measurement (or rather prediction, since intelligibility is not directly measured) of speech intelligibility.
%ALC (%Alcons)
Within a word or a syllable, consonants play a more important role in the understanding of speech than vowels, particularly in non-tonal languages such as English (in Chinese, for example, a tonal language, tonal inflections are an additional linguistic element that aids intelligibility). Interestingly, when we have to make ourselves understood above the ambient noise and try to shout, the results are usually not what we expect, and this is largely because, just as we can shout a vowel, it is difficult to pronounce most consonants at a high volume (try shouting the letter 't'!).
This importance of consonants led Victor Peutz in 1971 to develop one of the first indicators used for speech intelligibility, %Alcons, an acronym for Articulation Loss of Consonants, which attempts to translate the intelligibility of a room into a reduction in the perception of consonants, calculated either by measuring direct and reflected sound levels or by using the (mainly) architectural parameters of the room. The formula in the latter case is:
| 200 D² T² (n+1) | ||||
| %Alcons | = | | + | K |
| Q V M |
Where:
D = distance between the listener and the sound source
T = reverberation time (RT60) in seconds for 1400 Hz
K = Speaker/listener correction (from 1% for good speakers/listeners to 15% for bad ones)
Q = directivity factor of the loudspeaker (or talker)
n = the number of speakers
V = volume of the room in m³.
M = absorption coefficient of the area covered by the speakers
(Peutz's original formula was somewhat simpler, without the last three parameters)
You can see that the most important parameters (since they are squared in the formula) are the distance (D) between the person and the source and the reverberation time (T), and as secondary parameters the number and directivity of the speakers,
There are also more complex formulas for the calculation of %ALC based on the measurements of direct sound levels, reflected sound and ambient noise from an analyzer.
A %ALC above 15% is considered unacceptable, acceptable for simple messages from 15% to 10%, good between 10% and 5%, and excellent below this.
The %ALC has largely fallen out of use, partly because it is calculated for only one frequency.
STI
One element that is common among the latter techniques of objective measurement is that the different frequency bands are evaluated separately and more weight (importance) is given in the overall final score to those whose contribution to the intelligibility of the word is greater. For example, the 2k Hz octave is the most important, accounting for over 30% of intelligibility, and will contribute the most. Also, between the 1000, 2000 Hz and 4000 Hz bands more than 75% of speech intelligibility is attained. The graph below shows the contribution to intelligibility for the different octave bands.
Contribution to intelligibility by octave bands
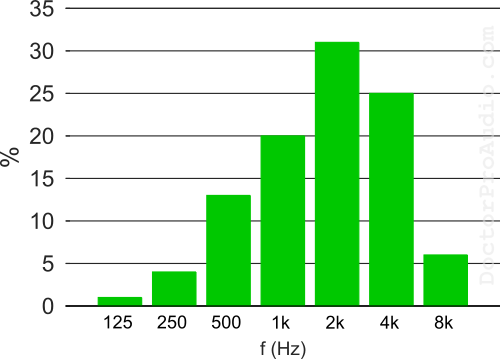
In the case of the STI (Speech Transmission Index), developed in the early 1970s by the Dutch Tammo Houtgast and Herman Steeneken, and based on pink noise octave bands that are amplitude modulated (i.e., the volume goes up and down like a tremolo effect) at different speeds (based on the volume inflections of actual speech), and which predicts the intelligibility of speech that is transmitted by a system that lies between the speaker and the listener, and whose values range from 0 (completely unintelligible) to 1 (completely intelligible).
The concept can be heard in this video in which an octave of noise centred at 1000 Hz is first played back with its amplitude being modulated at 1 cycle per second. This same pulsating noise is played back with added reverberation: the ratio of the maximum to the minimum level is reduced audibly and visibly.
If we have to modulate 7 different frequency bands of noise at 14 different speeds, the result is 98 different tests to obtain the same number of Transmission Indexes (TI), which are ratios between the signal and the noise (that being the noise itself or anything other than the original signal, such as reverberation, echoes or distortion). The average of the transmission indexes for the different modulation speeds in each band is then calculated, resulting in the Modulation Transfer Index (MTI, Modulation Transfer Index) for each of the 7 bands. These MTIs for each band are then combined into a single STI value, for which the different octave bands are deparately weighted according to their contribution to speech intelligibility. For example, the octave band centered on 2000 Hz has the greatest weight, since the 2k is more important than the other bands with respect to speech intelligibility.
When all of the the different octave bands and modulation speeds are applied sequentially (for a direct calculation), the duration of the test is about 15 minutes, although under certain assumptions an indirect calculation (which has become the most commonly used method and which will be discussed later) from an impulse response is allowed, in which case a result can be obtained within a few seconds. In both cases, in the presence of fluctuating noise the tests must be performed at least 3 times.
It was not until the end of the 1980s that the use of STI began to take off following the definition of an accelerated measurement method, RaSTI, the appearance in 1985 of the first commercial measurement system (by Brüel & Kjaer) and the publication of standardised measurement methods in the IEC 60268-16 standard ("Sound system equipment Part 16: Objective rating of speech intelligibility by speech transmission index") in 1988.
The calculation algorithm specified in the aforementioned standard has changed with successive editions. In addition, a differentiation between female and male speech was added in 1998 that did not originally exist (though it was later removed in the 2020 edition).
Unlike the %ALC, the STI is better the higher the value. Thus, we can establish this intelligibility scale based on STI values for native speakers and listeners without hearing or understanding problems.
| Intelligibility qualification for native listeners | ||||
| STI value ranges |
Intelligibility according to IEC 60268-16 |
Intelligibility of syllables in % | Intelligibility of words in % | Intelligibility of sentences in % |
| 00,3 | Bad | 034 | 067 | 089 |
| 0,30,45 | Poor | 3448 | 6778 | 8992 |
| 0,450,6 | Fair | 4867 | 7887 | 9295 |
| 0,60,75 | Good | 6790 | 8794 | 9596 |
| 0,751 | Excellent | 9096 | 9496 | 94100 |
The fourth edition (2011) of the IEC 60268-16 standard defines an alphabetic qualification scale that ranges from "U" to "A+":
| STI qualification bands and typical applications | ||||
| Category |
Nominal STI value |
Type of message information |
Examples of typical uses (for natural or reproduced voice) |
Comment |
| A+ | >0,76 | Recording studios | Excellent speech intelligibility but rarely achievable in most environments | |
| A | 0,74 | Complex messages, unfamiliar words | Theatres, speech auditoria, courts, Assistive Hearing Systems (AHS) | High speech intelligibility |
| B | 0,7 | Complex messages, unfamiliar words | Theatres, speech auditoria, courts, Assistive Hearing Systems (AHS) | High speech intelligibility |
| C | 0,66 | Complex messages, unfamiliar words | Theatres, speech auditoria, teleconferencing, parliaments, courts | High speech intelligibility |
| D | 0,62 | Complex messages, familiar words | Lecture theatres, classrooms, concert halls | Good speech intelligibility |
| E | 0,58 | Complex messages, familiar context | Concert halls, modern churches | High quality PA systems |
| F | 0,54 | Complex messages, familiar context | PA systems in shopping malls, public buildings' offices, VA systems, cathedrals | Good quality PA systems |
| G | 0,5 | Complex messages, familiar context | Shopping malls, public buildings' offices, VA systems | Target value for VA systems |
| H | 0,46 | Simple messages, familiar words | VA and PA systems in difficult spaces | Normal lower limit for VA systems |
| I | 0,42 | Simple messages, familiar context | VA and PA systems in very difficult spaces | |
| J | 0,38 | |||
| U | <0,36 | |||
Note 1: These values are to be regarded as minimum target values.
Note 2: Perceived intelligibility for each category will also depend on the frequency response at each listening position.
There are formulas that correlate the %Alcons with the STI. Similarly, modeling programs calculate the STI based on formulas that use architectural parameters and attempt to approximate actual measurement results.
The fifth edition (2020) of the IEC 60268-16 standard, a technical revision, adds information on prediction and measurement procedures, updates the relationships between STI and other speech intelligibility measures, takes some from weight off 125 and 250 Hz bands, and removes the differentiation between female and male speech, opting for the worst case scenario (male speech is less intelligible than female speech).
RaSTI
Each of these tests, from which each of the 98 transmission indexes is extracted, takes an average of about 10 seconds, such that a full direct STI test (in which each frequency band is played for each modulation speed) takes about 15 minutes, a very long time considering several positions need to be tested (and a number of tests will have to be run at each of them if there is unstable background noise). To expedite this process, already in the first edition of IEC 60268-16 there was the possibility of a shortened measurement (RaSTI, acronym for Rapid STI) in which only two frequency bands were used: the 2000 Hz band (with 5 modulation speeds) and the 500 Hz band (with 4 speeds, different from those used for the 2000 Hz band); furthermore, for a faster test, nowadays a single signal containing the two frequency bands and all modulations is usually reproduced, and the bands are then separated by processing.
Today RaSTI has fallen out of use, since there are fast ways to evaluate all the necessary bands.
STIPA
The second edition of IEC 60268-16 introduces (1998) the STIPA, an improved version of RaSTI that uses all seven frequency bands with modulation speeds for each one (all different to achieve the 14 different speeds of the complete STI measurement). This provided a faster measurement (originally about 60 seconds) more reliably than with RaSTI, which has become obsolete over time but is still used as a reference.
With the advent of digital technology, STI measurement was further accelerated by the fact that a single signal was reproduced with all modulated frequencies. In the player below we can play the signal for the STIPA measurement from an analyzer manufactured by NTI. It sounds static because there are seven different frequency bands with volumes going up and down at different speeds in each).
STITEL
In our industry, the element that deteriorates speech intelligibility the most is reverberation. However, STI is designed to include the effect of any element between the talker and the listener, including microphones and any other type of distortion, such as difficulties in receiving a radio or TV. STITEL is also defined in IEC 60268-16 specifically to assess telecommunication systems and is similar to STIPA, although with a single modulation rate for each of the seven frequency bands.
Today there is a multitude of analysers in the market that can measure STI and derivatives, either handheld or computer based. STI must be measured in different positions, and several measurements must be made at each position, particularly if the ambient noise is not constant. Some analysers allow the ambient noise and the test signal to be measured separately, and then the index calculated, which is practical in certain applications where people generate most of the ambient noise (e.g. in a stadium, where reproducing the signal with the audience present may not be an option). The test signal can be fed into the mixer of the PA system, or an artificial voice or small speaker can be used to reproduce the signal in front of the microphone, so as to include the microphone and surrounding acoustics.
Indirect methods
The objective measures of intelligibility that we have described so far are direct measurement methods. Whether you play single bands modulated at a different speed each time, or you add them all up into a single signal (like the player's STIPA signal above) and then break it down into each of the frequency bands for calculation, the measurement is direct.
However, later versions of the STI standard allow the calculation to be based on an impulse response (usually calculated from a frequency response with amplitude and phase, either MLS or swept sine), so the measurement becomes really fast.
A limitation of both the indirect method and the measurement with a single signal with all frequency bands being reproduced at the same time is that they are not able to include the effect of ambient noise, as the signal volume is never zero (although there is the possibility of adding a noise level parameter later). It is also not possible to include the possible effect that some bands may have on others.
In addition to more or less complete direct or indirect measurements, electroacoustic system modelling software also offers the possibility of mapping intelligibility levels based on direct sound levels, a prediction of reflected sound levels and noise levels that can be specified. The picture shows the variation of the STI in a reverberant station-type enclosure from an optimal level in front of the single loudspeaker at ear level to very low intelligibility values at the back of the building. To a large extent these variations in STI (and therefore in intelligibility) reflect the variations in the ratio of direct to reflected sound level.
Other indices
There are other intelligibility indexes that we have preferred not to include for ease of understanding and because they are not as widely used.
- The AI (Articulation Index) is an old index similar to the STI but does not consider the effect of reverberation on intelligibility, as it is based primarily on the effect of ambient noise.
- The CIS (Common Intelligibility Scale), proposed at the end of the last century, gives a different reading of the STI, applying the formula CIS = 1 + log (STI).
- The C indicators for Clarity deserve a separate mention. They express, in decibels, the relationship between the sound that arrives initially and sound that arrives later, the time in milliseconds that separates both being declared in the name of the index . For example, in clarity indicators C7, C50 and C80 this division is at 7, 50, and 80 milliseconds, respectively. The C50 is usually taken as a speech clarity indicator (a value greater than 0 dB is recommended for this purpose), while the C80 is used for musical clarity and should not be less than -3 dB (a requirement that could be reduced to -5 dB, for sacred music), while
- the C7 should be greater than -10 or -15 dB, depending on the criteria.
Something similar to the Cs are the D (Definition) indexes, that express, in percentage, the ratio between the sound that arrives initially and the total level, the time in milliseconds where the initial energy in considered to end being declared in the name of the index. In the case of D50, a value greater than 50% is recommended (a ratio greater than 0.5). - The U indexes are intended to express mainly the relationship between useful and harmful sound ('useful-to-detrimental sound ratio'). They are somewhat similar to the C indicators but also incorporate the noise level. They also define the division between initial and delayed reflections (e.g., U50, for which values above +2 dB are recommended for the 1 kHz band in speech intelligibility applications) and are given in decibels.
3. Improving intelligibility
As discussed, there are two main factors that make intelligibility difficult, noise and reverberation.- Noise
As for the ambient noise, there is often not much we can do about it (for example, in a stadium, where the noise of the crowd can be deafening). In any case, for the message to be understandable we will have to design a system that can generate a real continuous sound pressure (taking into account factors such as signal dynamics, which implies not using the maximum power of the amplifier to make the calculations, and taking into account other factors that can reduce the sound pressure such as the heating of the speaker coils) at least 10 dB above the noise.
This is imperative in voice alarm evacuation system applications. If the building is not constructed or is to be renovated, noise should be a factor in the design. For example, ensuring sufficient sound insulation to sufficiently reduce outside noise. Or, for example, in a road tunnel, preventing noise from ventilation turbines from being a problem. - Reverberation
The ratio of direct to reflected sound is usually the most important element that will determine intelligibility.Although the reverberation time does not help, it is primarily a low ratio between the two that will reduce the STI. In a reverberant church or station, we may be able to perfectly understand a person speaking next to us or the message being played when we are directly in front of a speaker; the problem arises when we walk away, since the level of the reverberant field competes with the direct sound.
In this sense, the design of the sound system should avoid sending a lot of sound to live surfaces that generate reverberation such as ceilings and walls, but also to areas of the room where there is no audience. When the amount of public is variable, we can consider turning off the emission to empty areas by means of a stored preset that easily reconfigures the system for the user. Depending on the application, a distributed system that brings the sound sources closer to the audience may be preferred, or else a central system with good directivity control at all frequencies that could be problematic (and here it is important to remember that, in order to generate directivity at low frequencies, size matters, and it may be necessary, for example, to have a loudspeaker array large enough to achieve directivity control at the problem frequencies). Modelling in these cases can give us an estimate before choosing the type of system, providing averages and other statistics, as it is sometimes difficult to estimate based on colour maps. - OthersSound quality and intelligibility usually go hand in hand, but they are not the same. A speech system can be highly intelligible but unnatural. In any case, the system components must be of sufficient quality. We have probably all heard those cheap portable megaphones used in demonstrations where even outdoors and near the device it is almost impossible to understand the slogans if we do not know them beforehand. Microphones are particularly important, and must be able to pick up speech clearly; this is sometimes the most economical way to improve the intelligibility of a voice alarm system.
Distortion can be a critical factor, although its effect is not usually seen in intelligibility measurements. If the audio is coming from a video conference, an adequate connection speed will be important to achieve and maintain sufficient audio quality without dropouts. On the other hand, distortion is not always negative for intelligibility: there are also forms of distortion that generate additional harmonics can improve the comprehension of a speech message such as an amount of clipping (saturation).
Equalization and other processes. Ideally the frequency response will be uneven and show no change between different positions beyond the natural loss in highs due to the coverage angle. Peaks or valleys in the frequency response that are common to all positions can benefit from corrective equalization. In low-quality systems with reduced highs, increasing the level of the 2k and 4k Hz bands will increase intelligibility; similarly, using a high-pass filter to cut lows and mid-lows can help with message understanding if there is excessive reverberation in those frequency bands. When it comes to noise, there are systems that monitor the level of ambient noise and adapt the volume of the signal so that it is above it, avoiding excessive sound pressure levels when the ambient noise is low. Similarly, for microphone-based announcements, a compressor can help achieve the appropriate level.
User knowledge. The person who makes announcements with a microphone must receive a minimum of training. They should be aware that they should not speak with their lips making contact with the microphone (perhaps a small anti-pop filter can help) and should not move too far away from it. They should also speak at the appropriate level, vocalize and speak as intelligibly as possible in places with difficult acoustics.
EL Lombard effect. The Lombard effect or reflex is the natural unintentional tendency to modify speech so as to increase intelligibility in high background noise conditions. In addition to an increase in volume, the changes include speed, frequency, spectrum and duration of vowels (lengthening). Facial movements are also exaggerated. An equivalent effect is also observed when several musicians play or sing together, and also between animals.
 Sections menu
Sections menu News
News